1. 什么是Apriori算法?
Apriori算法是一种频繁项集挖掘和关联规则学习的经典算法。它的主要步骤是通过不断发现频繁项集,然后使用频繁项集产生关联规则。
2. Apriori算法的基本步骤是什么?
Apriori算法的基本步骤包括以下几步:
(1) 扫描一遍数据集,计算出所有单一项的支持度,生成频繁1-项集的列表。
(2) 通过连接频繁1-项集的列表生成候选2-项集,然后扫描一遍数据集,计算每个候选项集的支持度,以此生成频繁2-项集的列表。
(3) 通过连接频繁2-项集的列表生成候选3-项集,然后扫描一遍数据集,计算每个候选项集的支持度,以此生成频繁3-项集的列表,以此类推。
(4) 通过连接频繁k-1项集的列表生成候选k项集,然后扫描一遍数据集,计算每个候选项集的支持度,以此生成频繁k项集的列表。
(5) 通过频繁项集产生关联规则,计算每个规则的支持度和置信度,然后按照一定的阈值进行过滤。
3. Apriori算法的优势是什么?
Apriori算法的优势在于它能够有效地发现频繁项集和关联规则。它使用了一种基于先验知识的方法来剪枝候选项集的数量,从而提高了效率。Apriori算法还可以通过调节支持度和置信度阈值来发现不同层次的关联规则。
4. Apriori算法的缺点是什么?
Apriori算法的缺点主要是它需要多次扫描数据集,因此对于大数据量来说可能效率不高。Apriori算法的关联规则只考虑了支持度和置信度两个指标,忽略了其他因素,这可能会导致一些有用的关联规则被忽略。同时,Apriori算法的参数较多,调参也是一个比较麻烦的事情。
"数据挖掘算法实例分析:发现隐藏在数据背后的宝藏
"
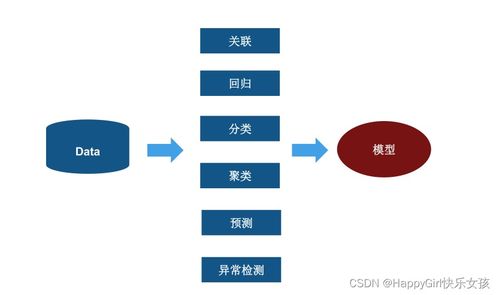
随着大数据时代的到来,数据挖掘算法在各个领域的应用越来越广泛。本文将以数据挖掘算法实例分析为主题,通过介绍几个典型的挖掘算法,探讨它们在实际问题中的应用和效果。
一、聚类算法:发现数据中的“物以类聚”

聚类算法是一种常见的无监督学习方法,它将相似的对象组织在一起,从而发现数据中的“物以类聚”。例如,在电商平台上,通过对用户购买行为的数据挖掘,可以将用户分为不同的群体,为不同群体提供个性化的推荐服务。常见的聚类算法包括K-meas、DBSCA等。
以K-meas为例,它通过迭代寻找数据集中的K个簇,使得每个数据点到其所属簇的质心距离之和最小。在电商平台上,可以利用K-meas算法对用户的购买行为进行分析,将购买行为相似的用户分为同一类,从而为不同类别的用户推荐不同的商品。
二、关联规则挖掘:发现数据中的“前因后果”

关联规则挖掘是一种发现数据中变量之间有趣关系的方法。例如,在超市中,通过关联规则挖掘可以发现尿布和啤酒的销量存在一定的相关性。常见的关联规则挖掘算法包括Apriori、FP-Growh等。
以Apriori算法为例,它通过迭代寻找频繁项集,并利用频繁项集生成关联规则。在超市中,可以利用Apriori算法对销售数据进行关联规则挖掘,发现尿布和啤酒之间的相关性,从而为商家制定更加的营销策略提供依据。
三、分类算法:预测数据中的“未来趋势”

分类算法是一种常见的监督学习方法,它通过对已知标签的数据进行学习,预测新数据的标签。例如,在金融领域,通过分类算法可以对信用风险进行预测。常见的分类算法包括决策树、支持向量机等。
以决策树为例,它通过将数据集划分成不同的特征子集,从而实现对数据的分类。在金融领域中,可以利用决策树算法对信用风险进行预测。通过对已知标签的数据进行学习,建立决策树模型;然后,利用该模型对新的贷款申请进行预测,判断其信用风险。
四、回归分析:预测数据中的“数值变化”

回归分析是一种预测数值变化的方法,它通过对已知数据进行学习,预测新数据的数值。例如,在股票市场中,通过回归分析可以预测股票价格的波动。常见的回归分析算法包括线性回归、逻辑回归等。
以线性回归为例,它通过拟合一个线性模型来预测数值变化。在线性回归中,我们通常假设因变量和自变量之间存在线性关系。在股票市场中,可以利用线性回归算法对股票价格进行预测。通过对历史股票价格数据进行分析和学习,建立线性回归模型;然后利用该模型预测未来股票价格的波动。
数据挖掘算法在实际问题中的应用非常广泛。通过对聚类、关联规则挖掘、分类和回归等算法的实例分析,我们可以更好地理解这些算法的原理和应用场景。随着大数据时代的不断发展,数据挖掘算法将会在更多领域发挥重要作用。