数据挖掘算法实例分析
随着大数据时代的到来,数据挖掘技术变得越来越重要。数据挖掘算法能够从海量数据中提取有价值的信息,帮助企业做出更明智的决策。本文将以关联规则挖掘算法和聚类分析算法为例,探讨数据挖掘算法在实际应用中的实例分析。
一、关联规则挖掘算法

关联规则挖掘是数据挖掘中的一个重要分支,其主要目的是发现数据集中的有趣关系。关联规则通常分为两种类型:频繁项集和关联规则。频繁项集是指在数据集中频繁出现的项的集合,而关联规则则是描述项之间的有趣关系。
以超市销售数据为例,我们可以通过关联规则挖掘算法发现商品之间的销售关系。我们需要确定频繁项集。假设我们设定的最小支持度阈值为0.2,这意味着只有出现次数占数据集总记录的20%以上的项集才被视为频繁项集。通过计算,我们发现“面包”、“牛奶”和“鸡蛋”是频繁项集,因为它们在数据集中出现的次数超过了20%。
接下来,我们可以利用频繁项集生成关联规则。假设我们设定的最小置信度阈值为0.7,这意味着只有置信度大于70%的关联规则才被视为有趣的关联规则。通过计算,我们发现“面包”、“牛奶”和“鸡蛋”之间的关联规则为:“面包-u003e牛奶”和“牛奶-u003e鸡蛋”。这意味着如果一个顾客购买了面包,那么他很可能会购买牛奶;如果一个顾客购买了牛奶,那么他很可能会购买鸡蛋。
通过关联规则挖掘算法,我们可以帮助超市制定更有针对性的营销策略,例如将面包、牛奶和鸡蛋放在一起销售,以提高销售额。
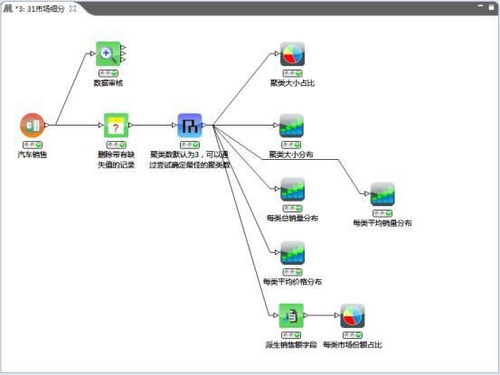
二、聚类分析算法

聚类分析是一种无监督学习方法,它将相似的对象组织在一起。聚类分析的主要目的是将数据集划分为若干个簇,使得同一簇内的对象尽可能相似,不同簇的对象尽可能不同。
以客户细分为例,我们可以通过聚类分析算法将客户划分为不同的群体。我们需要确定客户的特征。这些特征可以包括客户的购买行为、偏好、地理位置等等。然后,我们选择合适的聚类算法(例如K-meas、层次聚类等)对客户进行划分。通过聚类分析,我们将客户划分为若干个簇,每个簇内的客户特征相似度高,不同簇之间的客户特征差异大。
通过对不同簇客户的行为进行分析,我们可以发现不同群体的购买偏好和习惯。这将有助于企业制定更加的市场营销策略和产品开发计划。例如,针对不同群体的客户推出符合他们需求的产品和服务,提高客户满意度和忠诚度。
关联规则挖掘和聚类分析是数据挖掘中的两个重要算法。通过实际应用案例的分析,我们可以发现它们能够帮助企业从海量数据中提取有价值的信息,指导企业做出更加明智的决策。随着大数据技术的不断发展,数据挖掘算法将会在更多的领域得到广泛应用。