数据挖掘算法总结与反思

一、引言

随着大数据时代的到来,数据挖掘技术已成为处理和利用大量数据的重要手段。数据挖掘是一种从大量、模糊、随机、不完全的数据中提取隐藏在其中的有用信息和知识的技术。本文将概括介绍数据挖掘算法的不同种类,包括聚类算法、分类算法、关联规则挖掘算法、序列模式挖掘算法等,并对这些算法进行总结和反思。
二、数据预处理

在数据挖掘过程中,数据预处理是至关重要的一步。原始数据通常存在缺失、错误、异常值等问题,需要进行清洗、整理、归纳和转换等操作,以便为后续的挖掘算法提供更好的输入。数据预处理包括数据清理、数据集成、数据变换和数据归约等步骤,可以大大提高数据挖掘的效率和准确性。
三、聚类算法

聚类算法是一种无监督学习方法,用于将相似的对象组织在一起。聚类算法通常用于客户细分、市场划分、异常检测等领域。常见的聚类算法包括K均值聚类、层次聚类、DBSCA等。这些算法各有优缺点,需要根据具体应用场景选择合适的算法。聚类算法的评估通常使用轮廓系数、Caliski-Harabasz指数等方法。
四、分类算法
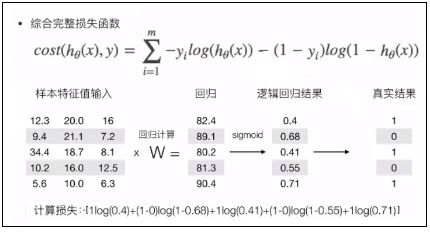
分类算法是一种有监督学习方法,用于预测对象的类别或属性。分类算法通常用于分类问题,如垃圾邮件识别、疾病预测等。常见的分类算法包括决策树、朴素贝叶斯、支持向量机等。这些算法的选择取决于数据的特征和问题的性质,如数据的分布、类别数、特征之间的关系等。分类算法的评估通常使用准确率、召回率、F1得分等指标。
五、关联规则挖掘算法

关联规则挖掘算法用于发现数据集中的有趣关系和模式。关联规则通常用于市场篮子分析、推荐系统等领域。常见的关联规则挖掘算法包括Apriori、FP-Growh等。这些算法通过频繁项集挖掘和规则生成等步骤来发现有趣的关联规则。关联规则的评估通常使用支持度、置信度等指标,同时需要考虑规则的实用性和可解释性。
六、序列模式挖掘算法

序列模式挖掘算法用于发现数据序列中的有趣模式和关系。序列模式通常用于时间序列分析、行为分析等领域。常见的序列模式挖掘算法包括Prefix-Spa、CD-Tree等。这些算法通过挖掘频繁序列和生成规则等步骤来发现有趣的序列模式。序列模式的评估通常使用支持度、置信度等指标,同时需要考虑模式的实用性和可解释性。
七、总结与反思
数据挖掘算法的应用范围广泛,包括但不限于商业智能、医疗保健、社交媒体等领域。不同的数据挖掘算法具有不同的优缺点和适用场景,需要根据具体问题选择合适的算法。在应用数据挖掘算法时,需要考虑数据的特征、问题的性质和实际需求等因素。还需要对数据挖掘的结果进行评估和验证,以确保其准确性和可靠性。未来,随着数据的不断增长和技术的发展,数据挖掘算法将面临更多的挑战和机遇。我们需要不断探索和创新,以更好地利用数据中的隐藏信息和知识。